

Methodologies presented herein are based on the SEG 2025 presentation by Sam Scher and Tom Carmichael, “Data Before Algorithms: An Open-Source Approach to Legacy Geochemical Method Categorization.”
Sit through enough conference talks and a pattern begins to emerge. Maps look polished, vectors appear convincing, and interpretations are delivered with confidence. Beneath that surface, structural problems in the underlying data may be discrete (pun intended) and sometimes obvious. The issue is not a lack of technical skill in interpretation. It is that many geochemical datasets are fundamentally inconsistent at their core. These inconsistencies are not always known, and even when they are, they are not always accounted for in interpretation. Mixed analytical methods lead directly to mixed messages, yet this remains a persistent problem.
Reported values are not universal truths: legacy datasets
At the heart of the issue is a misconception: geochemical values are often treated as directly comparable across time, programs, and laboratories. In reality, a reported value is not just a measurement; it is the outcome of a specific analytical pathway. Digestion method, analytical finish, detection limits, and sample preparation all impose structure on the data. As a result, two values for the same element from the same rock can legitimately differ purely because of how they were measured. Without recognizing this, it becomes impossible to distinguish geological signal from analytical artifact.
Where legacy datasets break down
Legacy datasets break down in predictable ways. Mixing digestion methods introduces systematic differences in element recovery, shifting distributions, and destabilizing ratios. What appears as geological variation is often a reflection of analytical inconsistency.
Detection limits further complicate the picture. They truncate distributions, introduce artificial thresholds, and can create apparent populations that have no geological meaning. If not explicitly identified, these effects can dominate statistical relationships and drive interpretation.
Additional variability is introduced through sample preparation and, critically, the absence of metadata. Without clear records of analytical methods, detection limits, and lab workflows, the dataset loses context. At that point, interpretation becomes inference rather than analysis.
The problem with “fixing” the data
In response, datasets are often “fixed” before export. Values reported by laboratories with qualifiers such as <, >, or BDL (explicitly indicating analytical limits) are frequently replaced with arbitrary numbers such as zero or half the detection limit. While this may simplify database structure, it removes critical information about how those values were measured. The distinction between measured and censored data is lost, and detection limits, which originally defined the structure of the dataset, are effectively erased.
Once these transformations are applied, the original analytical context cannot be recovered. What was once a transparent representation of measurement limitations becomes a dataset built on hidden assumptions. The data appear cleaner, but they are no longer faithful to the analytical process that produced them.
Further adjustments are often applied after the fact through levelling; correction factors, mean alignment, or regressions between surveys. These approaches attempt to force consistency, but in doing so they ignore analytical differences, break relationships between elements, and suppress real geological variability.
The result is not improved data, but redistributed bias. Apparent consistency is achieved at the cost of geological truth.
When interpretation becomes about the lab, not the geology
When these structural issues are not addressed, interpretation shifts away from geology. Clusters, trends, and anomalies begin to reflect analytical artifacts rather than lithology, alteration, or mineralization. Models built on this foundation become unstable and misleading.
This effect does not diminish with more advanced analysis – it intensifies. Multivariate methods and machine learning are highly effective at identifying patterns, but without an understanding of data structure, those patterns may reflect analytical bias rather than geological reality.
A shift in approach: start with data structure
A more robust approach begins with a simple but critical shift in perspective: before interpreting geology, the structure of the data must be understood. This involves examining which elements occur together and which are systematically absent, identifying the presence and consistency of detection limits, assessing whether data are continuous or discretized, and evaluating whether element ratios and correlations behave consistently. These characteristics provide insight into the analytical processes that shaped the dataset and form the basis for determining comparability.
In practice, however, this is not something that can be done effectively by hand. Attempting to identify these patterns across dozens of elements using traditional workflows (e.g., missing data analysis, probability plots, and iterative filtering) is not only inefficient, but it also quickly becomes unmanageable. In large, data-rich legacy datasets, the process becomes overwhelming, and the results are often inconclusive. The workflow breaks down under the complexity of the problem.
A different answer to the problem
To address this, we developed an approach grounded in two key principles: the original data are not altered, and analytical methods are not assumed. Rather than trying to correct or standardize the dataset, the focus shifts to classifying the data based on its inherent structure. By doing so, the integrity of the dataset is preserved, while enabling meaningful comparison and interpretation.
This approach emerged from the practical need to make sense of complex, mixed-method datasets in a way that was both systematic and scalable. Working collaboratively across geochemistry and data science, the workflow was developed, coded, and automated to move beyond manual, iterative methods that simply do not scale with modern datasets.
Reconstructing comparability: method families
At its core, the solution reframes the problem. Instead of forcing all data into a single analytical framework, the dataset is decomposed into “method families.” These families are defined by shared structural characteristics, including identical element suites, similar detection limits, and comparable precision and variance signatures. The goal is not to reconstruct the exact analytical method used, but to determine whether subsets of data are sufficiently similar to be used together. In doing so, comparability is restored without introducing artificial corrections or assumptions.
Going deeper: sub-families
Within these families, additional structure often emerges. Subtle variations in detection limits, precision, or analytical workflows can create sub-groups, or “sub-families,” that reflect batch effects, laboratory changes, or campaign-specific differences. Identifying these sub-families enables more targeted QA/QC, helps isolate noisier or less reliable subsets of data, and improves confidence in downstream analysis. The objective is not to redefine the chemistry, but to explicitly account for the analytical variability that would otherwise distort interpretation.
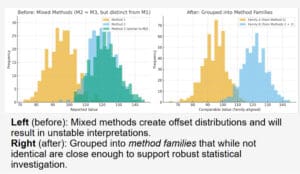
Interpret the Earth, not the artifact
The outcome of this approach is a dataset where geological signals can emerge more clearly. Element ratios stabilize, correlations become meaningful, and interpretations are grounded in the behavior of the rocks, soils, or mineral systems themselves, rather than analytical artifacts.
Legacy datasets are not inherently flawed, but they are not immediately comparable or interpretation-ready. They carry the imprint of analytical decisions (digestion methods, detection limits, sample preparation, and laboratory workflows) that, if unaddressed, will dominate the signal. The challenge is not simply one of data quality, but of data structure. When that structure is ignored, interpretation shifts away from geology; when it is imposed through “fixing” or levelling, those artifacts are not removed, they are redistributed.
This becomes increasingly important as the industry adopts machine learning and integrated workflows. These methods do not correct for poor data structure – they amplify it. Without an understanding of what is comparable and what is not, advanced models risk producing results that are precise, but wrong.
The goal is not consistency for its own sake. The goal is to ensure that what we interpret reflects the Earth, not the artifacts of how it was measured.
{kind=link}